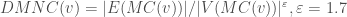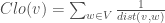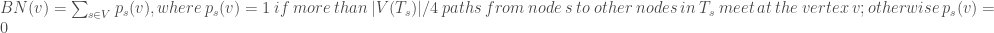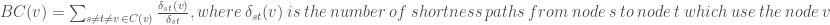想使用ubuntu:14.04基礎容器來做python程式prototype的工具,一方面,一些要使用的生資軟體只能在ubuntu環境下使用,另一方面,ubuntu:14.04算是很輕的小容器,希望讓最後的鏡像小一點。
這邊製作的容器主要是要使用bioawk和netMHC程式,所以dockerfile中會有安裝他的相關訊息。
這邊有幾個重點:
1. 安裝完所有jupyter需要的python library和ubuntu相關library
2. 在virtual environment中安裝jupyter
3. docker網路設置(port forwarding)
4. jupyter notebook網路設定(讓localhost以外的ip登入)
首先奉上dockerfile,裡面有所需的library
################################################################
# Dockerfile
# Version: 1
# Software: BioAwk/Jupyter
# Software Version: 201703
# Description: Basic image for Bioawk/Jupyter/Python3/plotly/numpy
# Provides: autotools-dev|automake|cmake|curl|fuse|git|wget|zip|build-essential|pkg-config|python2.7|python-dev|python-pip|zlib1g-dev
#################################################################
# Source Image
FROM ubuntu:14.04
################## BEGIN INSTALLATION ######################
# apt update and install global requirements
RUN apt-get update && \
apt-get install -y software-properties-common && \
apt-get install -y \
autotools-dev \
automake \
cmake \
curl \
fuse \
git \
wget \
zip \
build-essential \
gcc \
pkg-config \
csh \
tcsh \
byacc \
flex \
liblzma-dev \
lib1g-dev \
libblas-dev \
liblapack-dev \
gfortran \
libfreetype6-dev \
libpng-dev \
libjpeg8-dev
RUN apt-get install -y python3\
python3-pip
python3-dev\
python3.4-venv
Copy /bioapps /bioapps
WORKDIR /bioapps/
ENV PATH /bioapps/netMHC-4.0:$PATH
WORKDIR /bioapps/bioawk-master
RUN make
ENV PATH /bioapps/bioawk-master:$PATH
CMD ["/bin/bash"]
# change workdir
WORKDIR /var/data
RUN chmod 777 /var/data
RUN python3 -m venv test
RUN . test/bin/activate && pip3 install --upgrade pip && pip3 install -vU setuptools && pip3 install jupyter
RUN . test/bin/activate && pip3 install numpy && pip3 install plotly
##################### INSTALLATION END #####################
# File Author / Maintainer
MAINTAINER weitinglin <weitinglin66@gmail.com>
裡面安裝的東西主要由python pip3相關的依賴、bioawk在make時的依賴。過程會創建一個
虛擬環境test,並且在裡面安裝jupyter,和會使用到的package。
接下來,在運行這個容器的時候,要把port口掛在出來。
docker run -p 8888:8888 -it netmhc:latest
接者,在執行jupyter的時候,要用下面的指定
jupyter notebook --allow-root --no-browser --ip="*"
進入安裝有jupyter的python virtual environment
source test/bin/activate
執行jupyter,因為在docker container中,會是root模式,所以使用allow-root,另外,因為不需要直接跳開視窗,所以使用no-browser,最後,一個關鍵動作 –ip="*",讓所有外來ip都可以進入。過程中,有一些小技巧,比如pip3設定出現問題了,該怎麼刪掉再重新裝一次,可以使用apt-get purget python3-pip,然後再重新安裝一次。然後,會需要瞭解一下docker port forwarding的原理。
參考文章:
How to install pip with Python 3?
make bioawk錯誤,需安裝的檔案
安裝jupyter在ubuntu上面
ValueError “Expected version spec” when installing local wheel via pip
How to install pyzmq for iPython Notebook in a Python 3 virtual environment?
Networking features in Docker for Mac
From inside of a Docker container, how do I connect to the localhost of the machine?
Using localhost for to access running container
Jupyer notebook 安全性設定



![MNC(v)=|V(MC(v)|, where MC(v) \ is \ a \ maximum \ connected \ component\ of\ the\ G[N(v)]](https://s0.wp.com/latex.php?latex=MNC%28v%29%3D%7CV%28MC%28v%29%7C%2C+where+MC%28v%29+%5C+is+%5C+a+%5C+maximum+%5C+connected+%5C+component%5C+of%5C+the%5C+G%5BN%28v%29%5D+&bg=ffffff&fg=404040%3B&s=0&c=20201002)