最近在整理堆積如山的待閱讀論文,其中看到這邊撰寫於2010年的文章Gene-Expression Ontologies and Tag-Based Expression Profiling,通訊作者是Winston Hide教授,主要是探討CAGE資料的分析方式,因之前項目需求,稍微知道目前FANTOM計畫中,主要使用的技術便是根基於CAGE而來,因而產生興趣。

Winston Hide教授是學分子生物學出身,目前是計算生物學教授,參與英國的The 100,000 Genomes Project,本身有個部落格Element of Impact,最後一次更新是在2015年,他的學經歷非常豐富,也跑去在美國矽谷的超級電腦公司MasPar(已倒)工作過,學術經歷則橫跨美國、南非(在南非時參與pan-african genomic project)再到英國University of Sheffield任職神經科學轉譯醫學研究部門的負責人。
他的研究方式通常都會從調控的角度著手,使用整合性分析的方式(偏生物資訊手法),也會開發生物資訊的工具如CAGExploreR。
E. Dimont, O. Hofmann, S. J. Ho Sui, A. R. R. Forrest, H. Kawaji, the FANTOM Consortium, and W. Hide, “CAGExploreR: an R package for the analysis and visualization of promoter dynamics across multiple experiments.” Bioinformatics, Mar. 2014.
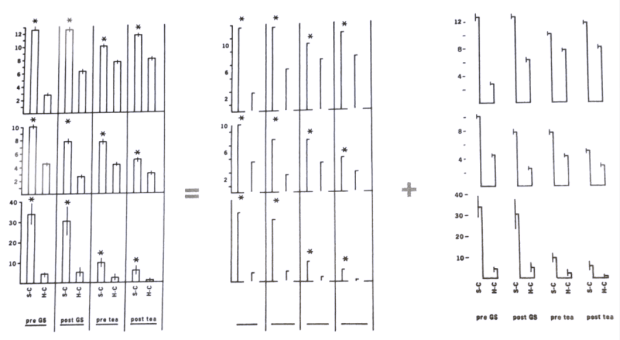
這篇的軟體已經沒有在維護惹,在Oxford雜誌上面的圖也看不太到,有點可惜!
FANTOM Consortium and the RIKEN PMI and CLST (DGT), “A promoter-level mammalian expression atlas.,” Nature, vol. 507, no. 7493, pp. 462–470, Mar. 2014.
K. L. Kathrein, A. Barton, Z. Gitlin, Y.-H. Huang, T. P. Ward, O. Hofmann, A. DiBiase, A. Song, W. Hide, Y. Zhou, and L. I. Zon, “A network of epigenetic regulators guides developmental haematopoiesis in vivo.,” Nature Cell Biology, vol. 15, no. 12, pp. 1516–1525, Dec. 2013.
假如對於基因調控機制的研究有興趣,那麼一定要關注FANTOM計畫相關的論文
C. J. Sandberg, G. Altschuler, J. Jeong, K. K. Strømme, B. Stangeland, W. Murrell, U.-H. Grasmo-Wendler, O. Myklebost, E. Helseth, E. O. Vik-Mo, W. Hide, and I. A. Langmoen, “Comparison of glioma stem cells to neural stem cells from the adult human brain identifies dysregulated Wnt- signaling and a fingerprint associated with clinical outcome,” Exp Cell Res, vol. 319, no. 14, pp. 2230–2243, Aug. 2013.
G. M. Altschuler, O. Hofmann, I. Kalatskaya, S. J. Ho Sui, A. V. Krivtsov, S. A. Armstrong, L. Stein, and W. A. Hide, “Pathprinting: An integrative approach to understand the functional basis of disease.” Genome Medicine, vol. 5, no. 7, p. 68, Jul. 2013.

很經典的手法,他把GSEA的觀念放入pathway分析中,將一個個pathway作為單位來看有無顯著,蠻有創意的方法,期待後續的發展。
N. Tiffin, E. Adie, F. Turner, H. G. Brunner, M. A. van Driel, M. Oti, N. Lopez-Bigas, C. Ouzounis, C. Perez-Iratxeta, M. A. Andrade-Navarro, A. Adeyemo, M. E. Patti, C. A. M. Semple, and W. Hide, “Computational disease gene identification: a concert of methods prioritizes type 2 diabetes and obesity candidate genes.” Nucleic Acids Res, vol. 34, no. 10, pp. 3067–3081, 2006.