在爬梳藥物基因體相關資料時,很重要的便是去理解藥品的編碼系統,因為同一類藥品通常名字有很多種,不同國家的藥物編碼也不同,常混者商品名等等,使用編碼系統可以免去名稱混亂所造成的問題,且要是有一套國際使用的編碼系統變可以使得國間的資訊可以共通。目前世界常用的藥物分類編碼系統有兩種,一種是AHFS(American Hospital Formulary Service)/DI(Drug Information)和WHO(World Health Organization)/ATC(Anatomical Therapeutic Chemical Classification)。傳統上使用這套系統便能做很好的藥品項目管理、評估用藥品質、效益分析等等(因為有統一的代碼,所以各國資料可以彙整在一起,所以當要把基因資訊跟藥物彙整,當然會需要使用到藥物編碼系統)。
這邊來記錄一下ATC code的系統:
一個藥物的完整ATG code總共有七位由英文和數字組成,由左到右,不同位置代表的東西不同,共分成五組,分別代表一個藥物所主要作用的器官系統、治療哪類人體功能問題、藥物化學組成的成分、藥物動力學上的組別來表示:
第一層:第一位,為一個大寫字母,總共有14個字母,代表藥物主要作用的目標人體器官系統
A: Alimentary tract and metabolism
B: Blood and blood forming organs
C: Cardiovascular system
D: Dermatologicals
G: Genito-urinary system and sex hormone
H: System hormonal preparations, excluding sex hormones and insulins
J: Anti-infectives for systemic use
L: ANtineoplastic and immumodulating agents
M: Musculo-skeletal system
N: Nervous system
P: Antiparasitic products, insecticides and repellents
R: Respiratory system
S: Sensory organs
V: Various
第二層:第二三位,由兩個數字組成,代表藥物所屬於的治療功能類別
ex: C03 Diuretics
第三層:第四位,為一個大寫字母,代表藥物在藥物動力上的組別
ex: C03C High-ceiling diuretics
第四層:第五位,為一個大寫字母,藥物在化學特性上的組別
ex: C03CA Sulfonamides
第五層:第六七位,為兩個數字組成,藥物實際所屬於的分子特性組別
ex: C03CA01 Furosemide


 )
)
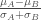


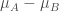
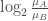
 ,假如不是,那麼就減
,假如不是,那麼就減 ,最後在過程中得到的最大值就是所謂的Enrichment Score
,最後在過程中得到的最大值就是所謂的Enrichment Score
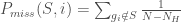

 閱讀參考:
閱讀參考:









