會需要用到Neo4j是因為在剖析Reactome資料庫中的生物路徑資料時,發現他有提供Neo4J的資料庫備份檔案,可以直接下載後,匯入到Neo4j的資料庫,相對於Reactome提供的BioPAX檔案,置放在Neo4j中的資料schema比較偏向原生他們內部人員所設計的(在寄信跟Reactome內部人員討論時,他們也推薦我試試看,直接使用他們的Graph資料庫的備份),所以直接瀏覽和理解它內部的資料架構時,可以少轉一層,只能說有好有壞,相對於在處理BioPAX檔案格式時,直接使用Apache tdb/arq相關工具土炮來取得裡頭的檔案,Neo4J則提供蠻多操作選擇的,主要分成可以由命令行操作和網頁模式操作,而在讀取資料庫的時候,可以使用內建的Rest API直接去做資料的爬梳處理。
跟RDF/XML或是其他Triple store的資料庫,Neo4j比較偏向’單純’的圖形資料庫,也就是並沒有那麼重視資料間關係定義的“語意”,更注重在“資工面向”所在意的點,效能、操作介面、API接口、進階的Query方式,Neo4j有自己開發一套query的語言叫Cypher,相信在理解SPARQL後,其實在理解相關圖形資料庫的獨取值會顯得容易許多。
瀏覽器的使用介面
可以使用圖形介面來匯入資料庫,然後把Neo4j服務啟動

可以直接登入Neo4j所開啟的服務,其有產生一個很好理解和管理的介面
不得不說它內部的文檔非常豐富
也可以直接使用命令行來讀取資料庫,因為其有良好的API接口,當然可以用curl直接來對街,也能用Java, .NET, Javascript, Python, Ruby, PHP等寫好的函庫(本來有一個R的,但似乎原本負責人離職,後來就沒有支持了!)
curl -i -H "Content-Type:application/json" -X POST -u neo4j:neo4j http://localhost:7474/db/data/transaction/commit \
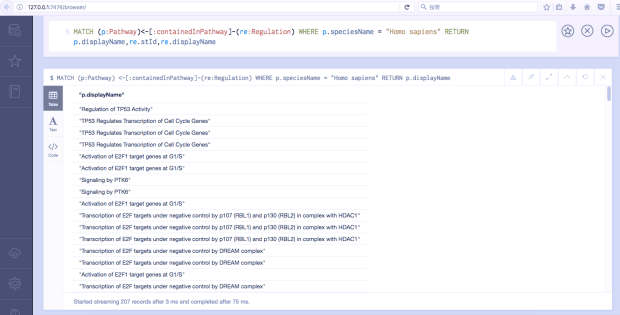
-d '{"statements":[{"statement":"MATCH (p:Pathway)<-[:containedInPathway]-(re:Regulation) WHERE p.speciesName = \"Homo sapiens\" RETURN p.displayName,re.stId,re.displayName ;"}]}'