回歸分析本是傳統統計學裡面很重要的一個領域,而近年來在計算機科學裡的“機器學習”也佔有一席之地,因其可以用來建立對於線性數值的預測模型。
Linear model always be your starting point
— Brian Caffo, Proffessor in Johns Hopkins
機器學習某個角度來說就是數據+統計+演算法的結合,在冠上新的名稱,其中的重點在於如何不斷修正統計模型,已達到更好的預測效果,而數據越多,能做出更好的預測。
這邊簡單紀錄以機器學習觀點下的線性回歸,使用線性模型的好處是其對於:1. 模型訓練資料量相對需求小、2. .模型中的x和y的關係易於闡述、3. 可以建立出好的預測模型
當我們使用回歸方法來分析兩個連續變數之間的關係時,其實就暗示者他們之間有者因果關係,其中的"因"通常就以x代表(predictor, independent variable),"果"就以y代表(response, dependent variable)。也就是我們希望建立出來的模型,可以使用x來獲得y的預測值!
評估建立的線性模型,是否符合資料,可以使用兩種方式來確定:(很棒的簡介影片)
第一種,計算RMSE

簡單的說,RMSE是計算殘差(residuals)的標準差(standard deviation),越小值代表,使用模型預估出來的預測值和實際值的誤差越小,模型越接近真實情況,此模型的特性是會對數值中的特異值會有比較大的放大效果!
第二種,計算R squared
R squared 代表模型可以解釋預測出來Y值的變異性, 數值越接近1代表模型符合原始資料。
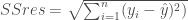

<pre>#import library</pre> library(tibble) library(dplyr) library(ggplot2) library(UsingR) data(galton) #import data dim(galton) str(galton) family.height.data <- as_tibble(table(galton)) #exploratory the data with scatter ggplot(data = filter(family.height.data, n > 0), aes(x = parent, y = child)) + geom_point(aes(size=n)) [/code ] #build the linear regression with lm package lm.height <- lm(child ~ parent, data = galton) parent.height <- galton parent.height$child <- NULL lm.predict.result <- predict(lm.height, parent.height) res <- galton$child - lm.predict.result #Two Ways of assessments #RMSE rmse <- sqrt(sum(res^2)/nrow(galton)) ``` 2.236134 ``` #R.square ss_res <- sum(res^2) ss_tot <- sum((galton$child - mean(galton$child))^2) R.squared <- 1 - ss_res/ss_tot
``` 0.2105 ```
summary(lm.height) [/code ] ``` Call: lm(formula = child ~ parent, data = galton) Residuals: Min 1Q Median 3Q Max -7.8050 -1.3661 0.0487 1.6339 5.9264 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 23.94153 2.81088 8.517 <2e-16 *** parent 0.64629 0.04114 15.711 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 2.239 on 926 degrees of freedom Multiple R-squared: 0.2105, Adjusted R-squared: 0.2096 F-statistic: 246.8 on 1 and 926 DF, p-value: < 2.2e-16 ``` #Visualization predict.data <- tibble(child = lm.predict.result, parent=galton$parent) predict.data <- as_tibble(table(predict.data)) %>% filter(n > 0) predict.data$child <- as.double(predict.data$child) predict.data$parent <- as.double(predict.data$parent) predict.data$type <- "predict" origin.data <- tibble(child = galton$child, parent = galton$parent) origin.data <- as_tibble(table(origin.data)) %>% filter( n > 0) origin.data$child <- as.double(origin.data$child) origin.data$parent <- as.double(origin.data$parent) origin.data$type <- "origin" total.data <- bind_rows(predict.data, origin.data) ggplot(data = total.data) + geom_point(aes(x = parent, y = child, colour = type, size = n)) + geom_abline(intercept = lm.height$coefficients[1], slope = lm.height$coefficients[2])

