關聯性分析(association rules analysis)在商業上早已很普遍的被使用,尤其是零售業者用來發覺顧客對購買不同商品間有沒有特殊的習慣,其中購物籃分析(market basket analysis)是最廣為人知且基礎的一種關聯性分析方法。這種分析方式有一個很重要的關鍵,便是需要大量的樣本,否則便沒有太大意義,另一方面,這不是一種能產生所謂“統計顯著”的分析方式,更多的是提供一個探索性的工具,能不能從結果產生有意義的東西,還是需要依據“領域知識”。
在過去使用這種“購物籃分析“方式於醫療或是生醫資料會是非常”可笑的“,因為每個實驗或是臨床試驗都是精準設計樣本數,想問的問題都是非常明確,然後才去設計實驗或是收集資料,希望從結果得到一個”顯著的意義“,但隨者越來愈多基因資料或是臨床資料的出現,很多時候其實也是在做一種”大海撈針“,或許這種購物籃分析也能使用來”探索“這些生醫資料,來產生一些有趣的”關係“,再進一步設計實驗來回答這種關係!
那什麼是購物籃分析呢?
購物籃分析是頻繁模式探勘(Frequent Pattern Mining)中的一種實現方法,目的是為了找出在資料中某些頻繁出現的連結,而使用association rule是這方法的關鍵,所以有時候又有人會稱為關聯性分析(association rule analysis)。這方法出現的背景是當我們想要探討某些東西/事物/購買物品一起出現或是某些東西/事物/購買物品不會一起出現的關係。在商場上購物的例子中,就是探討顧客所購買的商品之間,是否會有一些特出的關係存在!
這方法的邏輯脈絡如下,我們會先嘗試找出每次購物中各種物件/物品間一起出現或是反之的關係,然後可以從這些關係組合出各種可能,然後可以用下面的方式表現,即所謂association rule,每種關係都代表一種可能的關聯規則:
![computer=>antivirus\_software\[support=60%,confidence=60%\]](https://s0.wp.com/latex.php?latex=computer%3D%3Eantivirus%5C_software%5C%5Bsupport%3D60%25%2Cconfidence%3D60%25%5C%5D+&bg=ffffff&fg=404040%3B&s=0&c=20201002)
接下來,就是要有能評估一個關聯規則是不是所謂的frequent pattern,是不是我們所要找的,而這邊支持度(support)和置信度(confidence)這兩個指標邊能幫助我們理解個別項關聯規則對我們是否有意義,這兩個指標簡單來說分別代表這項關聯規則是否有用(usefulness)和可以確信(certainty)。所以通常我們會設下最下支持度闕值(minimum support threshold)和最小置信度闕值(minimum confidence threshold),當某項關聯規則能超過我們所設的闕值,才會成為我們所相信的關聯規則,而這闕值要怎麼設,則由領域知識來決定,並沒有所謂的標準,下面是者兩個指標的定義:
支持度(support)
資料中item set A和iterm set B在每一筆記錄中同時存在的機率
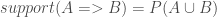
置信度(confidence)
在每一筆item set A存在的資料中,item set A和item set B同時出現的機率

有了上面的基礎架構,接者便是介紹將其實現的演算法,Apriori演算法算是最基本且常用的算法,R裡面的arules package便是使用這演算法
這邊放arules的使用代碼
library(arules)
#建立模擬的資料,裡面A和B這兩個item常常一起出現和消失
A <- c(rep(1,200),sample(c(1,0), size=800, replace = TRUE, prob = c(0.1,0.9)))
B <- c(rep(1,200),sample(c(1,0), size=800, replace = TRUE, prob = c(0.1,0.9)))
C <- c(sample(c(1,0), size=1000, replace = TRUE, prob = c(0.1,0.9)))
D <- c(sample(c(1,0), size=1000, replace = TRUE, prob = c(0.1,0.9)))
E <- c(sample(c(1,0), size=1000, replace = TRUE, prob = c(0.1,0.9)))
mimic <- data.frame(A,B,C,D,E)
#轉換成apriri函數可以接受的格式
trans <- as(data.matrix(mimic),"transactions")
rule.iter <- apriori(trans, parameter = list(support=0.2,
minlen = 1,
maxlen = 3,
ext = FALSE,
confidence=0.6,
smax = 1,
arem ="none",
minval = 0.1,
originalSupport = TRUE,
maxtime = 5))
#看運算後的結果
inspect(rule.iter)
關聯性分析的閱讀參考:
1. 白話大數據與機器學習, 第十一章
2. 數據挖掘:你必須知道的32個經典案例,第五章/第七章
在臨床或是生醫領域的應用論文:
1. Distance-Enhanced Association Rules for Gene Expression, Proceeding BIOKDD’03 Proceedings of the 3rd International Conference on Data Mining in Bioinformatics, 2003
2. Mining gene expression databases for association rules, Bioinformatics, 2003
3. Integrated analysis of gene expression by association rules discovery, BMC Bioinformatics 2006
4.Efficient mining of association rules for the early diagnosis of Alzheimer’s disease, Physics in Medicine and Biology ,2011
5. icuARM-An ICU Clinical Decision Support System Using Association Rule Mining, IEEE Journal of Translational Engineering in Health and Medicine,2013
6. Association rule mining based study for identification of clinical parameters akin to occurrence of brain tumor, Bioinformation, 2013
7. Association rule mining to detect factors which contribute to heart disease in males and females, Expert Systems with Applications, 2013
8. Validation of an Association Rule Mining-Based Method to Infer Associations Between Medications and Problems, Applied Clinical Informatics, 2013
9. Mining Association Rules in Dengue Gene Sequence with Latent Periodicity, Computational Biology Journal, 2015
10. Dynamic association rules for gene expression data analysis, BMC Genomics, 2015
11. Prediction of Metabolic Pathway Involvement in Prokaryotic UniProtKB Data by Association Rule Mining, PloS One. 2016
