21世紀治療法案後,所謂醫療大數據的時代,才算是逐漸到來,因為這法案實際在美國FDA裡面新增許多條例,主要是納入"真實世界的證據(Real-World Evidence)"作為FDA檢驗的資料之一,這包括藥物監視、醫療管理、醫療保險、電子病歷資料、流行病調查等,強調的是相對於“臨床試驗嚴謹設計下”,貼近病患“真實狀況下”的資料,詳細的法條內容可以看這邊,這方案通過非常多前衛的概念,用來加速或是接受一些新科技的出現,然後擁抱他們幫助醫療的進步連結 。
Real-World Data is data collected from sources outside of traditional clinical trials. These sources may include large simple trials, or pragmatic clinical trials, prospective observational or registry studies, retrospective database studies, case reports, administrative and healthcare claims, electronic health records, data obtained as part of a public health investigation or routine public health surveillance , and registries(e.g., device, procedural, or disease registries). The data is typically derived from electronic systems used in health care delivery, data contained within medical devices, and/or in tracking patient experience during care, including in home-use settings
—– FDA, Use of Real-World Evidence to Support Regulatory Decision-Making for Medical Devices
那到底這些新的證據或是資料間的關係要怎麼架構呢?下面這張圖很廣泛性地來闡述醫療數據,從下往上(基因分子層面),和從上往下資料(臨床電子病歷等)的急劇增長以及彼此的關係,這整合的過程並試產出新的“真實世界證據”。

可以簡單把這些資料來源分成:
1. 來自醫療體系內相關的資料(用藥、診斷碼、保險資料等等)
2. 電子病歷(EMR)
3. 基因分子資料
4. 病人自我量化的資料
下面這張圖表由Georgia Tech教授Mark L. Braunstein在他的Health Informatics on FHIR課程中所整理的,清楚的把這四大類資料來源,目前在分析上或是接受度的比較。

在這篇2013年JAMA的文章The Inevitable Application of Big Data to Health Care就提到數據量提高後,可以從哪幾個層面來改善醫療的進展:
1. 增加產生醫學知識的能力
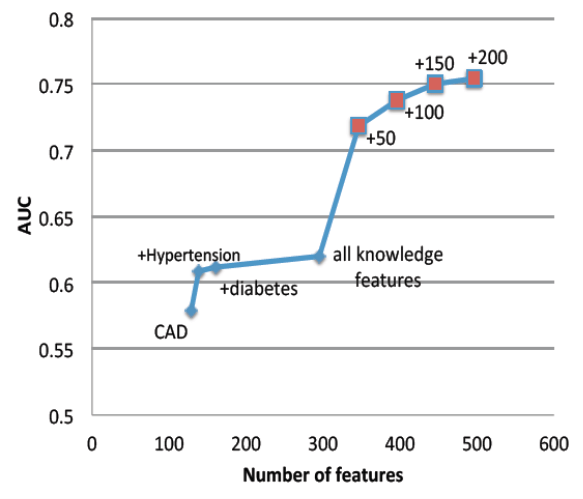
下面這張圖表是由IBM Watson研究小組的Jimeng Sun博士所做的研究,他想表達的是傳統Congestion Heart Failture的診斷是非常困難的,因為初期的臨床症狀非常細微,所以他加入了200多個非傳統臨床標的之預測因子,可以把診斷率提高。藉由這種方式,可以探索出以前所不知道的知識。
2. 幫助臨床決策
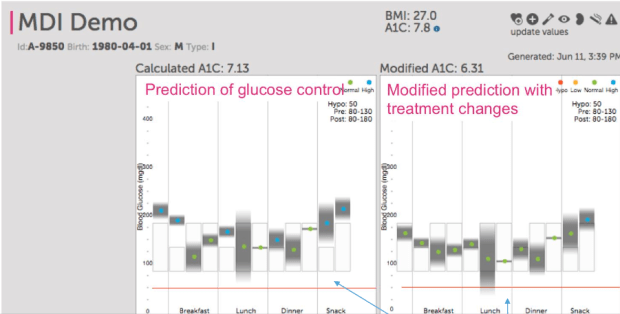
下面這個視覺化應用是由Rimidi公司所發展,為了解決糖尿病病人的血糖控制,在這圖型上,會整合病人過去到現在的血糖數值,整理出應該的變化,然後醫師可以根據所挑選的藥物,而圖型上會調整出,假如使用這藥物下,病人血糖可能的改變,藉此幫助醫師來做臨床決策。
3. 將分子層面基因組、表現組學等生物醫學知識轉譯成臨床使用
4. 改變醫療健康生態,讓資訊能更直接地讓每個場域中的人能享用
5. 加速產生新型態的醫療照護模式
閱讀參考:
1. 孫鑫,譚倩,唐立,于川,李靜,康德英,陳進,李幼平. 重新認識真實世界研究.(2017)中國實證醫學雜誌,vol.17,No.2
- Sheila Kaplan. Winners and loser of the 21st Centruy Cures Act(2016). STAT. Dec 5
 在設計Linked Data相關的schema時,最好能使用那些大家常用的,好處是能減少時間,提高開發效率,最重要的則是之後你所設計出來的database是可以跟其他用同樣schema儲存的資料做合併甚至提高一些inference的效果。
在設計Linked Data相關的schema時,最好能使用那些大家常用的,好處是能減少時間,提高開發效率,最重要的則是之後你所設計出來的database是可以跟其他用同樣schema儲存的資料做合併甚至提高一些inference的效果。
 近年來因
近年來因