癌症和一般組織之全基因轉錄體資料在瞭解細胞如何癌化有很關鍵的角色,而RNA-seq的技術是目前獲得完整轉錄體最佳的方式之一,但始終沒有一個好的資料庫能同時擁有以下的特性:
- 大量且有架構的資料儲存和分析結果
- 根據疾病別所分類
- 有良好視覺化或是經過分析的資料
而清華大學所建立的RNA-seq癌症資料庫:RNA-Seq Nexus,
是第一個擁有以上所有特性的資料庫,其有非常好的網路操作介面,且是開放給所有人可以用來做資料探勘等等的研究,是在做癌症研究或是精準醫療的科學家可以使用看看的。
這二十年來的基因表現研究都是以microarray技術為基底所建立的,像是Oncomine、NextBio、GCOD等等,但實際上,所有的gene都會spliced 成multiple transcript isoforms(90%的基因都會有spliced),也就是轉譯成不同蛋白質,很顯然的這種技術產生的資料對於真正的基因表現會有一些biase。而RNAseq技術可以取得這些isoform的資訊。
目前已有提供RNAseq資料庫的有Gene Expression Omnibus(GEO)、Sequence Read Archive(SRA)。但這些資料庫只提供原始檔案。這些資料還需要使用許多進階的生資處理技術才能把原始檔案轉化為可用的資訊。
美國NIH資助的The Cancer Genome Atlas資料庫儲存有大量基因體資料包含RNA-seq,缺點就是裡面只有從TCGA 相關計畫出來的資料。
Rna-Seg Atlas則是目前有提供RNA-seq expression profiles的資料庫,但是其只含有一個data sets,11個檢體。
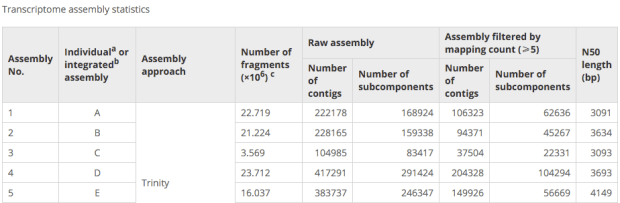
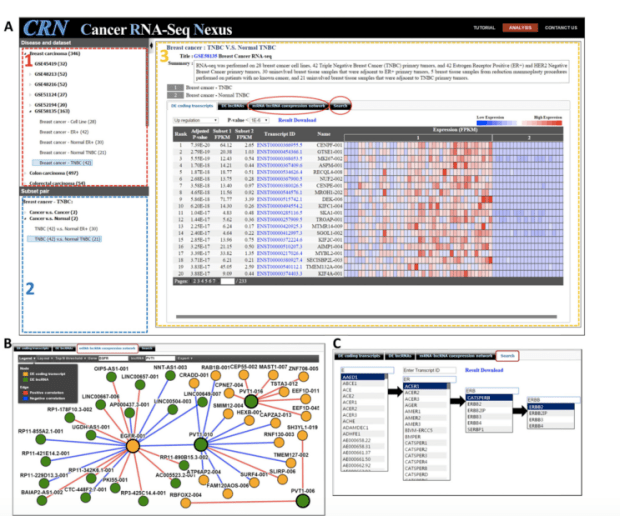
相對地,這次台灣清華大學建置的Cancer RNA-Seq Nexus資料庫裡頭有54組人類的癌細胞RNA-Seq data sets,且為phenotyp
-genotype分類好的。另一方面,提供良好的視覺好網頁操作,可以用來看coding-transcript/lncRNA expression profile.
原始文章
Li JR, Sun CH, Li W, Chao RF, Huang CC, Zhou XJ, Liu CC. (2015) Cancer RNA-Seq Nexus: a database of phenotype-specific transcriptome profiling in cancer cells. Nucleic Acids Res[Epub ahead of print]. [article]