
Introduction
- 多變量統計分析 | Multivariate Statistics
多變量統計分析相對於一般的(單一變量)統計分析更為進階,探討的層面也更為多元。學習正統的多變量統計分析,也許需要先修一些數學的工具,如線性代數、矩陣代數等等。然而並不是每個來自各個專業領域想要運用多變量統計分析的人都能熟悉那些生硬的數學工具,但它仍是社會科學、商學和生物學等領域重要的研究工具。
Biostatistics系列的文章希望以一個學過基礎的生物統計學、專攻於生物學專業的人的角度,進階的理解多變量樣統計分析原理和應用。
Example
[Multivariate Statistical Methods: A Primer, Figure3.4, p.31]
- 主成份分析 | Principal Component Analysis (PCA)
主成份分析(principal component analysis; PCA)現今被廣泛地應用於降低資料的維度(降維:dimension reduction),使得複雜的資料型態,能以簡單、少量的新變數解釋原有的資料型態,PCA更是許多多變量統計分析方法的基礎。PCA最早是在1901年,由Karl Pearson所提出一種可以用以「正確地」解決生物統計學問題的方法。不過他當時並未提出一個可以運算兩組或三組變數以上的的計算方法。直至1933年Hotelling才提出一套可行的運算方法,然而在電腦發明之前,僅能靠紙筆運算,因此也只能處理少量的變數。
PCA的目的是處理p個變數
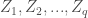
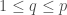

PCA的主成份遵循以下敘述的條件:
- 主成份根據變異度(variation)大小遞減排序,即
,
則表示在這組資料中
- 解釋變異度過小的
- PCA是將p個原始變數
轉換為q個新變數
,而過多的原始變數,有時可能無法有效地透過PCA降低該組資料的維度。
- 各個原始變數尺度、單位可能不盡相同,因此建議先進行標準化(z-score standardization,
)後再做PCA。
PCA的運算程序
適用於主成份分析的資料應是n個樣本(或個體),以及其p個變數。(如下表)
| Individual | X1 | X2 | … | Xp |
|---|---|---|---|---|
| 1 | x11 | x12 | … | x1p |
| 2 | x21 | x22 | … | x2p |
| … | … | … | … | |
| n | xn1 | xn2 | … | xnp |
而第一主成份(the first principal component)是變數
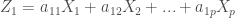
變數可能與樣本數一樣多(或更多?),且服從下列條件:

因此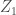
![Var[Z_1]](https://s0.wp.com/latex.php?latex=Var%5BZ_1%5D&bg=ffffff&fg=404040%3B&s=0&c=20201002)

第二主成份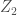

此外,若有p個變數,則至多會有p個主成份。
[進階] 以矩陣代數來運算PCA (1) 變異數矩陣法
然而對於實際的應用上,進行PCA並不必要去一一了解每條式子的運算,取而代之的,則是可以用一共變異數矩陣 (covariance matrix)解出其特徵值(eigenvalues)

矩陣的對角線(diagonal)元素



主成分的變異數是矩陣C的特徵值(eigenvalues. 


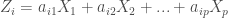
也就是說![Var[Z_i]=\lambda_i](https://s0.wp.com/latex.php?latex=Var%5BZ_i%5D%3D%5Clambda_i&bg=ffffff&fg=404040%3B&s=0&c=20201002)


一個重要的特性:eigenvalues的總和等於矩陣C對角線元素的總和(sum of diagonal elements = trace)

因為
[進階] 以矩陣代數來運算PCA (2) 相關係數矩陣法
為了避免原始變數造成恩PCA運算上的不良影響,因此將變數
原始變數經過標準化之後,矩陣C則會變為一相關係數矩陣(correlation matrix)

矩陣中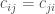
[Summary] Steps in principal component analysis
- (optional) 將原始變數標準化。
- 計算共變異數矩陣C;若有執行step 1.則為相關係數矩陣。
- 解出特徵值,及其對應的特徵向量。
- 捨棄解釋變異度比例過小的主成分。如,累計變異度達90%後,其餘的主成分則可忽略。
最後以一段YouTube影片來解釋PCA的原理
- R 實作 | PCA
在R裡面,主成分分析有兩道指令,分別為prcomp()和princomp(),網路上的教學以前者偏多,兩者的分析角度有些為差異,以下引用Reference 3. Principal component analysis in R : prcomp() vs. princomp() – R software and data mining 的說明:
The function princomp() uses the spectral decomposition approach.
The functions prcomp() and PCA()[FactoMineR] use the singular value decomposition (SVD).
實作練習RとS-PLUSによる多変量解析 3.3 主成分分析の実例:米国都市部の大気汚染(p.54)
Discussion
多變量統計分析在處理生物學、體學(-omics)資料上,可能遇到的問題
References:
- Multivariate Statistical Methods: A Primer, Second Edition. Bryan F.J. Manly. 1994. Chapman and Hall/CRC.
- RとS-PLUSによる多変量解析。B. エヴェリット (著), 石田 基広 (翻訳), 石田 和枝 (翻訳), 掛井 秀一 (翻訳)。2012。丸善出版。
- Principal component analysis in R : prcomp() vs. princomp() – R software and data mining
- LaTeX – Use of math symbols and equations.
- HTML Table generator.

最近看到生態學的文章便是撞牆在算特徵值~這篇看完比較了解概念了~日文的reference有點猛耶~
讚讚
其實日文我也看不懂 XD
也許我們R實作的時候,也可以來玩玩怎麼算特徵值、特徵向量
讚讚
那你會 SEM 嗎?
讚讚
不會耶 QQ
讚讚