陸奇前輩的演講,總是滿滿的乾貨,可以將這次的分享和四年前的做個比較,收穫良多,前一次的主題是針對人工智能時代的創新創業浪潮。下面的文字是利用先將youtube的影片字幕複製到文字黨後,用shellscript分段貼到chatGPT,幫忙整理而成,要是串API的話,應該會更快。

現代範式的改變
這次範式變革所代表的機會是由產業發展結構所決定的,其中包括生產資源和模型知識。模型知識使得成本結構由邊際轉向固定。這次變革在技術驅動社會發展的過程中扮演多重角色,其內在結構描述了技術如何推動人類社會的進步。基於這一內在結構,我們可以分析判斷這次範式變革在未來發展的幾個層面上具有何種重要影響。首先,這次變革驅動了新一代的科學發展方式,而科學進步是人類社會進步的最根本生產力。其次,人類的經濟發展體系是技術驅動的。技術的本質是運用科學可解釋的原理和能力改變自然現象,並利用資訊轉化人力以滿足人們的需求。
數字化帶來的三位一體:感知、思考、實現
社會經濟的發展可以理解成,人、組織、社會和數字化對於人類環境所產生的系統,這系統有感知、思考和實現能力。 這次數位化的範式變更將直接驅動模型和行動體系,用數位化的能力去轉化能源,將被大步的往前躍進。 數位化是人的延伸,是人自我認知和能力的延伸。 有了數位化的能力之後,我們將持續不斷的去改造世界。 要改造世界,必須要轉換能源,並且將能源轉化為信息。能源轉化只有兩種形式,一種是用生命體系來轉化,另一種是用物理體系轉化能源。此外,能源轉化不需要必須要有物理空間,這次技術革命將更快的驅動現代的空間技術。最後,科技將不斷的加快社會的進步速度。所以這次的變革將在更大程度上讓更多的企業成為科技公司,技術將更快的驅動社會經濟發展。

三個維度的變化
人類社會進展由技術驅動,每一次重大的進展都會帶來生產力、生產關係和社會關係的變化。 早期在農業社會之前,我們是遊牧民族,隨著農業技術的發明,人類生活方式在根本意義上發生了改變,我們開始定居,有了家。 再後來,人類社會進入工業社會,我們開始有更多自由,儘管農業社會給我們帶來了穩定,但限制了我們的行動自由。工業社會所帶來的,是給人更多的自由度,降低了人的體力勞動。隨後,資訊社會帶來了大量的資訊,我們的產業和社會從商品經濟進入了服務經濟,我們開始使用資訊和腦力勞動來產生商業價值和社會價值。 然而,今天的服務經濟也將面臨變革,因為我們所做的一切腦力勞動,除非有特殊的認知能力,都將在根本意義上被改變。 因為這一次,模型的成本降低,我們將很快從一個服務經濟進入一個體驗經濟。 在此過程中,我們認為創業者、科學家和藝術家等職業是最重要的,他們將帶來下一代的體驗經濟。 未來,當人工智慧和數位化體系無處不在,人的體力和腦力都不再需要時,我們將進入一個我們暫且稱之為AI經濟的時代。 在這個時代,我們將一起探索人的驅動力和行為將是什麼。 最後,由於數位化的能力,我們是否會回到新一代的遊牧狀態,因為我們不需要在任何一個地方固定下來。


OpenAI開啟的新時代:ChatGPT
我們如何去適應這樣新的範式變革,你需要用不同的方法去思考和實踐,我們可以從這個范式的締造者當中得到重要的啟示,這一次范式轉換的到來,在技術進步的角度來講,它不是水到渠成的,而是一個突破。以目前這個範式的締造者OpenAI為例,其推出的ChatGPT在短短兩個月內擁有全球一億活躍使用者,用戶願意付費並每天使用,這在歷史上前所未有。
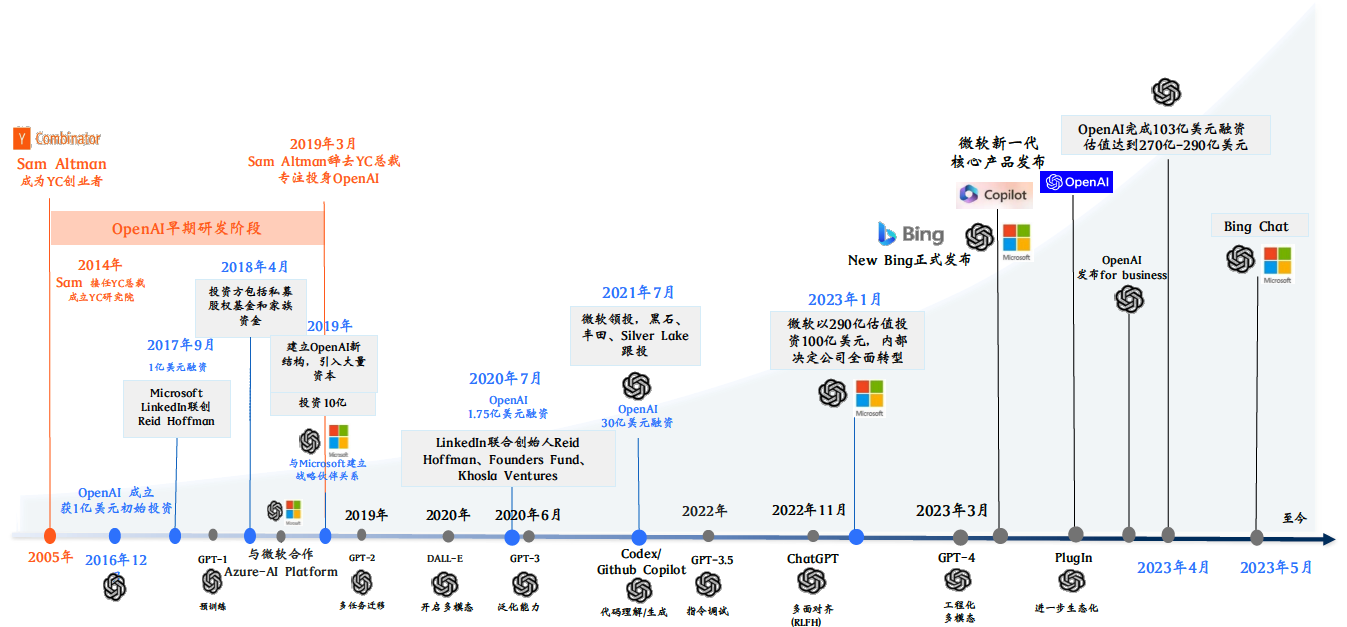
目前OpenAI已推出其ChatGPT最新版本GPT4,它是一種多模態、全面系統工程化開發的大模型。 在GPT4之後,外掛程式推動了生態的進一步發展。 OpenAI的團隊,由300多人組成,每月、每周都在高效緊湊地進展。 幾天前,微軟的團隊與OpenAI團隊緊密合作,將ChatGPT的引擎用於Bing。 一個團隊如果運用新的範式核心思考,實現新的範式,其創新能力將非常大,因此,在這個時代,深入解讀OpenAI的成長歷史,他們的思考方式和實踐對我們每個人都非常重要。
新的範式背後一定有核心技術,這些核心技術使新的範式成為可能。 新的範式之後,有一個新的動力引擎,這個引擎,本質上是一個模型體系,叫做GPT(Generative Pretrained Transformer),它有幾個重要的核心特性:
- 高效地訓練壓縮資訊,表達我們所知道的全世界的知識。 壓縮的越強,其代表的知識含量就越高。
- 模型能夠持續提高泛化能力,在更多參數、更多Token的情況下,新的能力會湧現,包括常識推理、算術和問題解決能力。
- 推理能力不斷增強和被探索,包括演繹、歸納和常識推理。
- 對齊是關鍵。 基礎模型能否使用,主要取決於是否對齊。 對齊工程和研究是最活躍的科研領域和工程開發領域。 對齊有幾個維度,包括對人的認知空間對齊(如語言、代碼、表格等),以及對人的價值觀對齊。
- 這個模型體系在現有的硬體和軟體基礎上,能夠充分利用更多的有效算力,如超級並行的GPU。
這個模型體系能夠處理重要的模態,如語言、圖像和視頻。在今天的硬件和軟件基礎之上,這個模型體系能夠充分運用更多的有效算力,如超級並行的GPU,因此模型可以使用更多的算力來發揮模型作用。
不段擴展和演化的模型
目前我們已經有足夠的模型擴展能力,如讓模型接入符號求解器,將符號運算能力接入,用這個模型學習如何使用這個工具。 因為transformer是一個通用的序列建模工具,不僅可以用於語言,任何其他模態也可以用transformer來建模。 大量的工具都在擴展,對於模型的擴散涌現,我們之前討論過它的多維度和可擴散性。 這個引擎是這個時代背後堅定的力量,因為模型的成本會從邊際向固定走,這就是靠這個引擎。 有了這個引擎之後,這個模型已經開始改變產業,並以非常高的速度將邊際成本轉向固定成本。
今天,我們可以訓練出能力不錯的大模型,例如10億甚至20億個參數 ,這已經足夠且可以有越來越多的應用發展,因為要使模型最終改變世界,它必須能夠在不同場景中使用,必須能夠小型化並能夠本地化。 在未來,我們將在每個手機端、每個IoT設備和每輛車上使用這個模型。
GPT4封裝了我們能夠得到的所有知識,封裝了學習能力和推理能力。界面是自然語言處理,任何人都能使用,這使得今天做大模型的成本已經沒有貴到大廠不能做,而且成本在不斷的降低。
GPT4在自然語言處理的概念,採取跟過去不同的策略,過去的自然語言處理領域,基本上將處理的思路是我能通過編寫軟體理解你的一句話。但這是錯誤的,因為要理解一句話,你需要有知識。 我可以分析這句話,知道這是形容詞、動詞、名詞,但關鍵是這個名詞究竟是什麼? 它可能是一包香煙,加油站,你的舅舅,或是電影裡的演員,你需要全球的知識來處理自然語言,另一方面,OpenAI首先使用知識進行自然語言處理,利用知識引擎針對語言對話進行調試,而不是先理解這句話,再拉入知識。 我們過去十幾年所做的,基本上是反的。 但現在自然語言處理已經完全通了,因為我們都使用過ChatGPT,過去的自然語言交互都令人緊張,怕他聽不懂,稍微換一換他就不對了,但現在,你基本上隨便講,他都能懂。 他有所有的知識封裝在裡面,利用這個知識作為基礎,根據對話進行調試,而不是反過來。 因此,這次自然語言處理的作用非常和諧,他將在範式攀升的過程中扮演重要的角色,我們歷史上從未有過如此有效、有用、任何廠家都能使用的交互工具。
我相信GPT5和6將有跨模態的泛化能力。 當然,更多的領域和應用,更多的基礎設施都在高速發展者,這個引擎的能力將越來越強這一點極其重要,因為大模型揭開了人類技術發展的新篇章。 我們引入了前所未有的新物種——模型。 無論是我帶到會議的50個模型,還是你給我提供的200個模型,我們都在與模型共事。模型是新物種,它的發展軌跡將決定我們的未來。 在本質上,這是一種進化,就如同Brian Arthur在《技術的本質》一書中描述的,技術的進化與達爾文的自然選擇非常相似,都是結構功能組合的選擇。技術的進化選擇是滿足人類需求更多的地方,因此大模型的未來將是一個進化的未來。

這個進化過程中,我關注的主要問題是系統1和系統2。 大模型目前主要基於信息系統1進行推演和推理。 系統1是快速思考,或者說直覺。 我們大部分時間都在用直覺,比如開車,只有在面臨大問題時,我們才會用邏輯去分析。 系統1的優點是它是過程性的,可計算的,基於場景的,可以解決我們生活中的問題。 而我們建立的模型,如愛因斯坦理論,牛頓理論等等,主要是系統2的模型,這些模型都是符號和數學公式,它們的優點是專業化,泛化能力強,但在我們的日常生活中幾乎沒有作用。
因此,我們需要的是系統1和系統2的組合,形成新的組合模型,能夠更有效地解決問題,在Meta模型的示意圖中,可以看到這種進化已經在發生,一代一代的模型都在湧現,我們無疑正處在這個新物種爆發的寒武紀時代,每天都有新的子物種出現。
總的來說,我們高度重視大模型以及衍生出的子模型的進化過程。今天的模型生態在某種程度上類似我們已知的生物系統,大模型就像基因,衍生出的領域模型就像表觀遺傳學,最終都是進化的過程,形成了真正的智能體系。
經濟發展格局的轉變
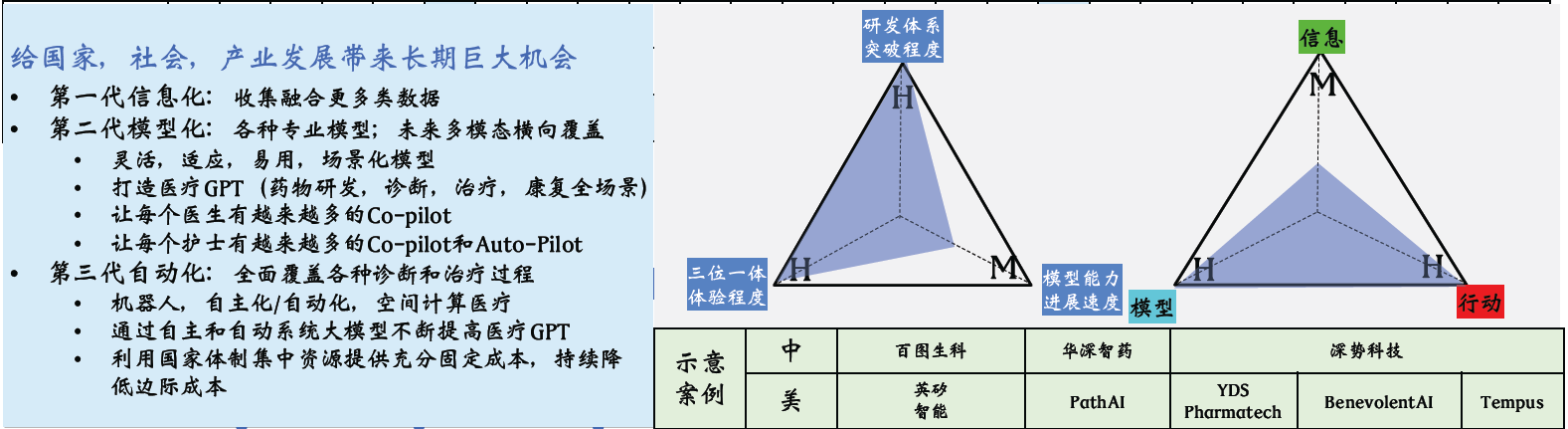
我們已經分享了新範式的內在結構,發展體系和所需的核心思考維度。 接下來,我們將探討這個新範式帶來的新時代將如何發展。 社會經濟發展是我們最關注的,其發展格局將在全球範圍內形成。 這個新範式的發展速度和動力將是前所未有的,因為它改變的的生產力是知識,知識的力量無窮,是最強的生產力,改變的維度是首要的。 這個生產力變得便宜,如今碼農、律師等高工資行業將受到影響,這些模型將變得越來越便宜。 這個生產力將在知識密集產業如醫療產業中發揮巨大作用,用大模型技術可以提高醫生和護士的水準,提升產業生產力。
在這個過程中,模型的研發速度會加快,生產力的反覆運算速度和創新速度也將加快。因此,攀升速度將非常快。這次變革將影響到人類的每一個職業種類,每個人都將開始使用副駕駛員,等待其能力越來越強,最終變為正駕駛員autopilot。 我們每個人都將擁有一個pilot team,人與人之間、人與機器之間的合作將成為未來社會企業的組織方式。
這個經濟發展格局將影響到我們每一個人的每一個工作崗位。變革的先鋒將是數字化產業,它將開拓新的商業價值。整個數位化產業將全面提高和更新,我們將擁有新的核心技術堆疊、新的平臺、新的基礎設施、新的算力體系、新的通訊體系以及新的產品開發體系,一切都將以大模型時代為主。
數位化產業的發展將影響所有行業,每個行業都將系統性、結構性地遷移到未來狀態。模型將改變知識結構成本,從邊際成本轉向固定成本。未來企業需要重新評估各項開支,以適應這一變革。我們可以預見,使用大模型技術將提高各行業產出,如軟體、設計、分析等領域的需求將大大增加。 最後,根據每個產業的特點,我們可以預測未來每個行業的結構性變更將從哪個方向發展,以什麼樣的速度來發展。
我們可以想像,利用大模型技術,可以顯著提升程式設計人員、設計師、分析師以及醫生等各行業工作人員的產出。每個行業結構性的變更,都將根據不同的方向和速度進行。同時,政府的參與和監管將更加積極,特別是在安全、數據隱私和社會穩定方面。例如,OpenAI在美國和歐盟地區的發展,政府出臺的早期參與就表現得尤為顯著。 此次變更需要社會產業與政府進行更多互動,尤其在早期扶持和引導基礎設施投入,以及全球性的發展上。
OpenAI產業生態系的形成

OpenAI產業生態,現在正在高速發展,其生態結構已經形成,因為它目前領先不少。它的平臺就是GPT,現在是GPT 4。OpenAI的後台開發出了新的模型,前臺是ChatGPT,它是一個人類歷史上從未有過的自然語言交互介面。 同時,它還有一個可擴展介面,就是ChatGPT Plugin,已經有大量的應用可以在這個平台上開發。人類歷史上從未有過自然語言交互的介面,比如ChatGPT。同時,ChatGPT也做了一個平臺的可延伸介面,即ChatGPT Plugin,已經有許多應用在此基礎上開發。OpenAI前後台每天都有大量的應用在被開放,OpenAI自己也有一個完整的生態佈局,通過投資以及與YC的關係驅動,生態的健康成長是當前最關鍵的,這是我想與大家分享最重要的資訊。在數位化產業的發展中,開發者的介面和生態是最重要的。

接下來我們討論模型開發。基礎模型開發沒有生意可做,因為都是大廠自研,但它非常重要。我們必須理解追求大模型的路線圖。 模型開發有幾個關鍵環節,首先是數據體系,包括數據集、語料、標註系統、標註工具和數據開發管線。 其次是模型體系,其中有參數深度、模態和token等因素。 第三是集群體系,需要合理地組合算力資源。 在大模型時代,我們需要的不是伺服器,而是幾萬張卡在一起,每張卡必須能直接訪問記憶體。 訓練體系也很重要,包括指令調試、正則化、Epoch、損失函數、對齊體系以及安全體系。 有了這些基礎,我們就可以構建一個系統化的工程體系,進入一個持續反覆運算進展的狀態。
最後,讓我們看看大模型之後的領域模型,基於已有的大模型,我們可以通過知識蒸餾、微調或提示等方法進行優化。 最近的熱門話題是參數有效的微調,通過少數GPU和足夠的token,就可以微調出一個相當不錯的模型。
我們採用知識蒸餾、微調和提示等方法進行模型優化。 最近,PEFT和參數有效的微調技術,例如小LoRA,受到了大家的熱烈追捧,尤其是在開源世界。 只需少量的GPU和足夠的token,就能微調出一個相當不錯的模型。 數據集中包含了語言學數據和知識圖譜數據,都是很重要的資源。
新一代的API和服務公司如雨後春筍般嶄露頭角,其中,由斯坦福的PhD Lamani創辦的公司值得我們關注。 因為在開發領域模型的過程中,我們需要各種開發方法,包括多模態開發,例如Midjourney正在進行的二維圖像、視頻和遊戲資產生成專案。
目前,主要依賴擴散模型,如stability和LoRA Controlnet,但這些都還在早期,需要大量的工作去形成穩定的持續攀升狀態。隨著大量工具公司的加入,我們的產能會提高。領域模型的進展也相當激動人心,尤其是在參數優越的微調方面,近幾周的進展非常快,出現了很多開源的大模型。 輕模型可以運用到端上,利用知識蒸餾、數據蒸餾、結構優化和量化縮小等手段優化。 長期來看,我們必須將大模型用到端上,這需要大量的研發工作。
開源模型的角色
最後,我們非常關注開源,因為開源是降低整個創新門檻的關鍵。 LLaMA體系是開源體系中最活躍的部分,它的衍生品LLaMA adapter引起了很大關注。 小模型也非常活躍,同時,Databricks、Cerebas、Mosaic AI等公司也表現出色。我非常高興看到美國有許多活躍且有志向的創業者在探索開源模型,開源數據非常重要。 英語是人類歷史上第一個真正的全球語言,我們的語言模型需要大量的英語語料,如common crawl、Wikipedia、書籍、文章數據等。
在模型開發方面,我們還在早期,但已有大量的進展。 大模型、領域模型、邊緣模型和開源模型都在同步開發,更重要的是,開發應用也在同步進行。 基礎開發代碼的工作流、代理機制提示調試和記憶embedding都需要我們關注,因為有大量的應用需要開發。
我把開發能力的拓展叫做自然語言寫代碼,這是非常重要的,我們可以通過試用不同的提示,使用自然語言形成一個抽象的知識結構,並根據需要進行推理和規劃,這個探索空間實在太重要了,我們歷史上從來沒有過讓每個人都能通過自然語言進行開發的機制,當前的框架還不夠穩定,我們需要更完整、更可靠、更穩定的工具,但這隻是時間問題,一定會發生。
我們需要開發對象,運行時非常重要。後端雲服務是目前最常見的運行環境,大部分開發都在雲端進行,原來的SAAS正在逐步變成MAAS,在手機端和移動端上開發一個繁榮的開發生態系統,有新機會等待大廠和有勇氣的創業者,IOT端也很重要,因為大模型必須要在每一個埠都能落地,為其他開發者生態提供長期的機會,吳恩達的課和Oreilly的課都值得關注,預計會有很多書、論文和Github repo上的代碼與數據,未來發展速度和寬度取決於開發堆疊,誰搶佔開發者心智,誰掌握著未來的大量發言權。
新范式下的機會
技術驅動能力很重要,范式擴散需要三個方面:科研、高品質代碼和商業化。 政府也很早參與其中,全球主要有兩個地區:美國北美和中國,這次擴散與個人密切相關,聰明勤奮努力的人會學會使用這個工具,個人的行為如學習、探索、創新變得至關重要,無論你是創業者、創作者、程式師還是科學家。這次認知能力工具的擴散會拉開人與人之間的距離,與個人有很大關係。 那些聰明、勤奮、努力學會使用這個工具的人,會很快拉開與同等水準的人的距離。
創業公司應著眼於系統性探索,關注創始人團隊的心力、願力和能力,引入新的人才和建立組織文化,形成一個強盛的體系。 早期的重點是開發各種能力,包括技術能力、產品能力、交付能力、增長能力、商業價值能力和獲取資本能力,長期去實現它的價值空間。

我們需要思考如何掌握這個機會,首先,不要盲目追求熱度,需要思考清楚再行動。 其次,勤於學習,這次新的範式是複雜的,需要多次理解才能真正掌握。 最後,一旦想明白,必須行動,因為這次的變革是“不進則退”。
對於一個企業,存在三個考慮維度。 第一,你的產品和業務是否有新的機會,如何探索其中的風險; 第二,你所在的產業是否正在經歷根本性的變革,你是否應該佔據新的市場位置; 第三,你所在產業的研發體系和能力是否徹底轉變,你是否需要換一個全新的思路去做事。
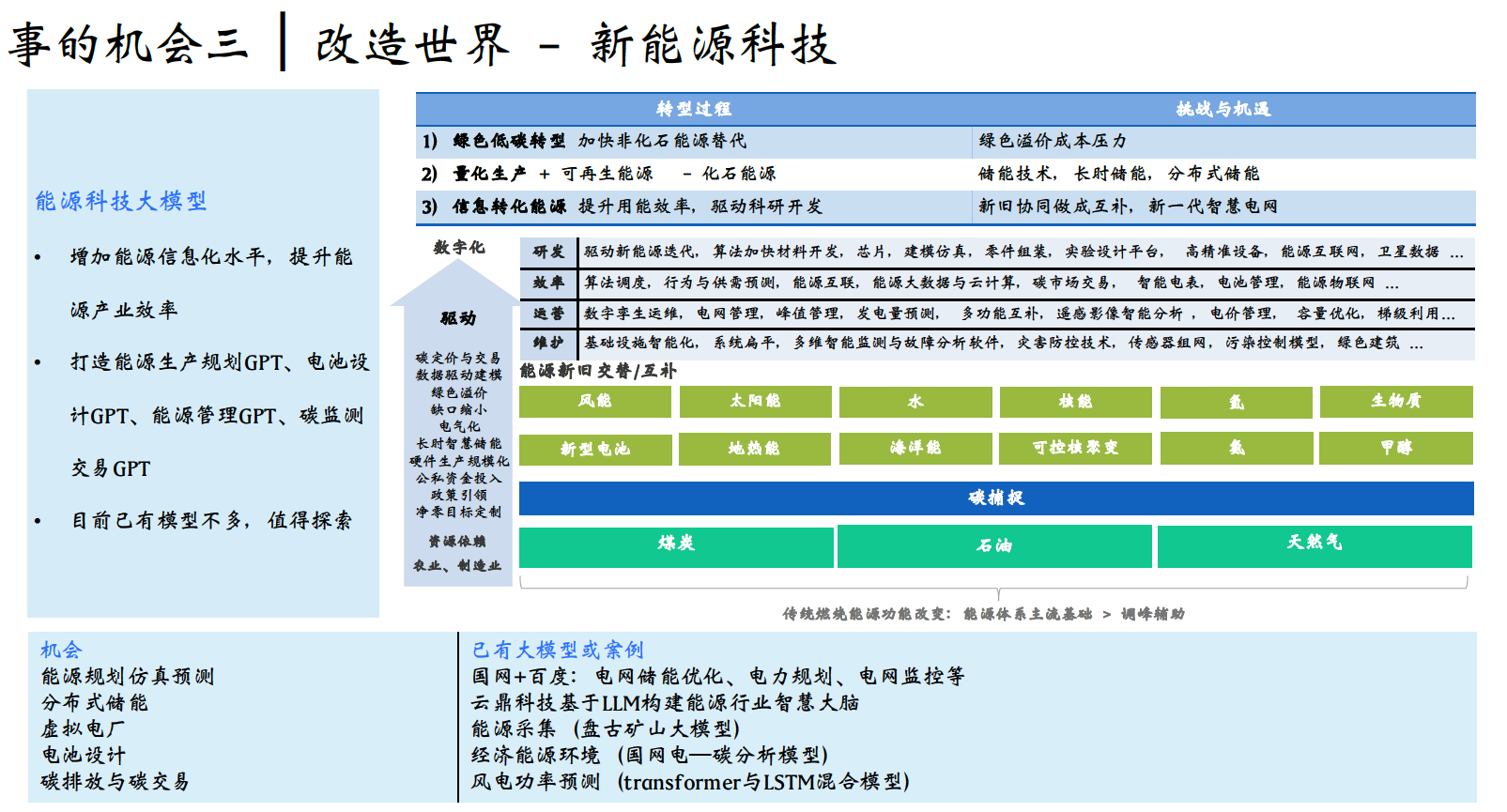
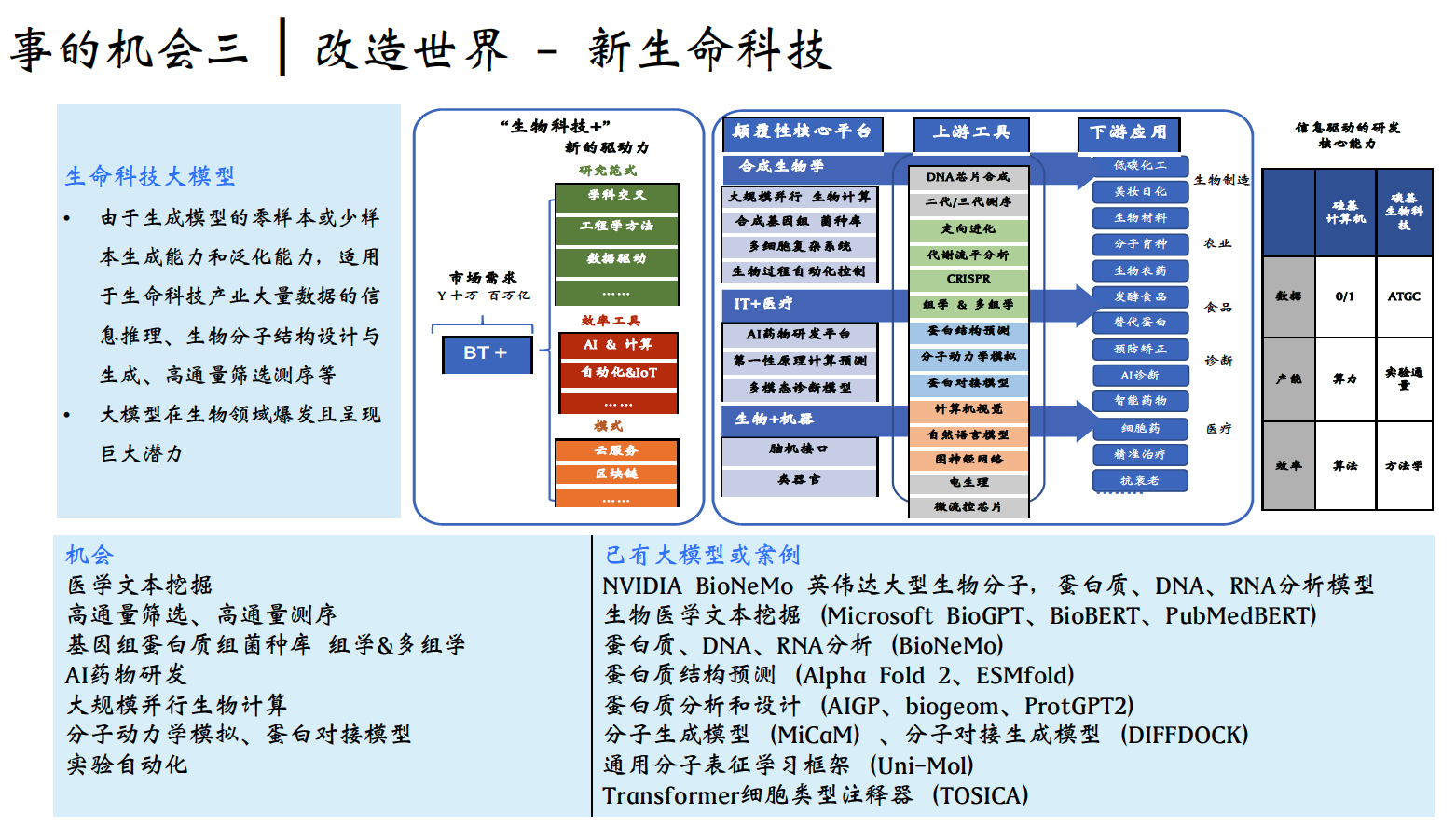
我們為大家提供了一個系統性的框架,這個框架包含三個機會板塊,我們用這個框架來指導所有的投資和與創業公司或創業者的互動。 第一,人類的本質是認識世界並改造世界,人類是一個減熵的物種; 第二,我們通過數位化來擴展自身,因此數位化是一大機會,它驅動著整個人類的進步,包括基礎設施平臺和數位化應用兩個子板塊; 第三,改變世界的力量來自能源、生命科學、材料科學和空間科學。







閱讀參考:
