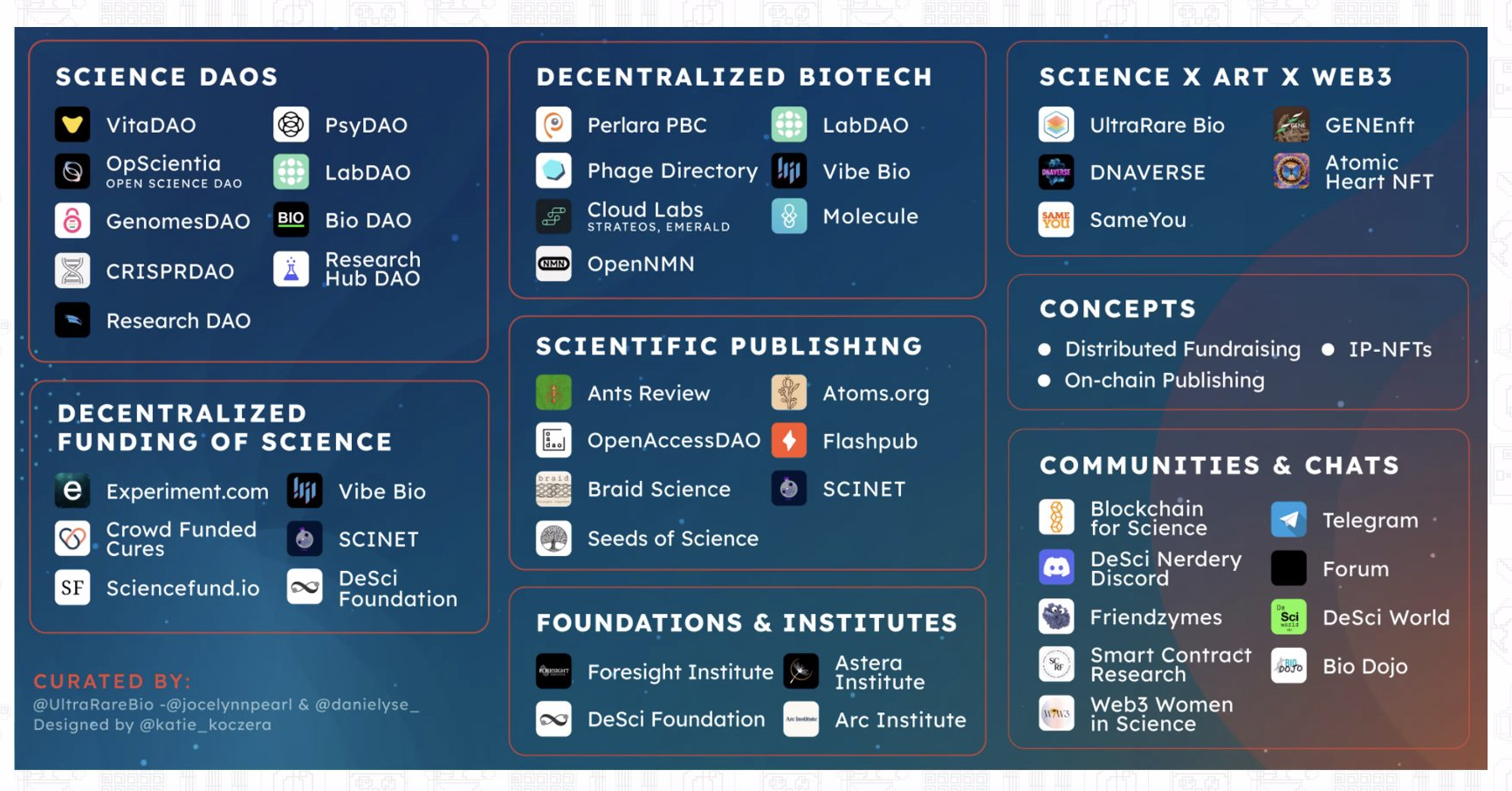
四月份科學月刊生物資訊大解碼相當吸引我,特定去訂了紙本雜誌來蒐藏,看裡面會怎麼去分享這個非常重要且多元的領域,雖然所謂的生物資訊領域已經至少十年以上,但其內涵和產業大概每五年都會有蠻多不同的技術系統出現。

這集封面故事主要有四篇文章組成:
- 生物資訊學是什麼? 結核生物學、統計學、資訊學的科學。 — 林志鵬
- 生物醫學資訊科技帶領醫療數位轉型-用程式寫未來的精準醫療。— 張明台
- 以『次世代定序』完成精準醫療,更能協助生命科學領域的探索 —趙盈婷、許藝瓊
- 學習生物資訊學要具備哪些能力?李御賢教授專訪 — 林翰佐
四篇文章都是用淺顯易懂的方式來分享這領域的看法和知識。
第一篇生物資訊是什麼,是由林志鵬所撰寫,他是英華達醫療電子事業部資深經歷,銘傳大學兼任助理教授,曾任有勁基因研究服務銷售總監。
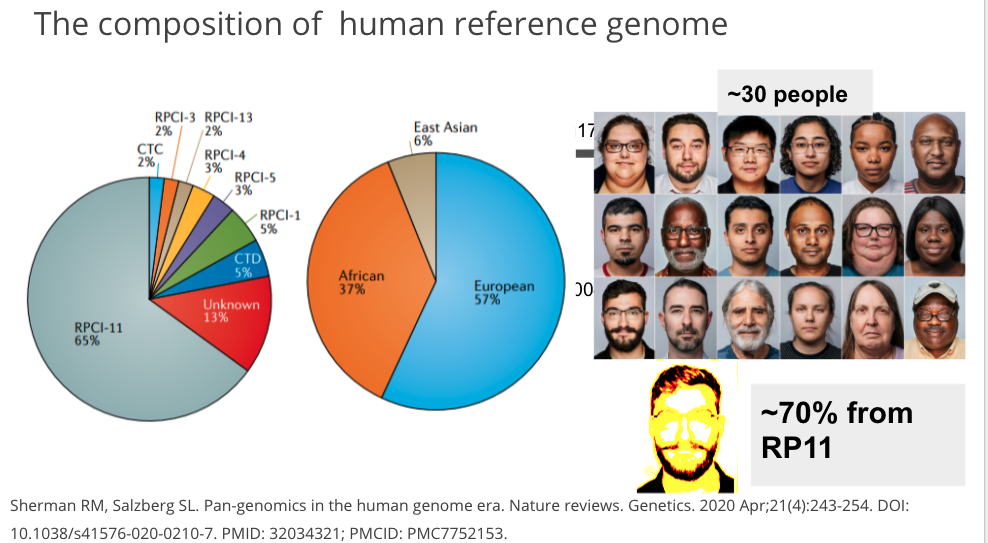
- 1989,美國人類基因體計畫(Human Genome Project)的開始,2007年次世代定序地出現,從10年30億美元定序一組簡略且錯誤百出的參考基因組,到2天內解碼48個人類的基因。
- 最原始的生物資訊,探討生物核酸序列的異同: 美國國家生物技術資訊中心的BLAST
- 從核酸序列的分析到蛋白質結構的預測:蛋白質資料庫(Protein Data Bank, PDB),從1994年還有蛋白質結構預測的關鍵評估(Critical Assessment of protein Structure Prediction, CASP)比賽,近年來的機器學習也開始被應用於這類巨量資料之中。
- 2015年美國總統歐巴馬提出的精準醫學計畫(Precision Medicine Initiative),預計搜集100萬人的基因資料用於疾病診查使用。
- 2020年的自然期刊上,刊登英國10萬人的全基因組定序計畫(UK100K),顯示出英國政府在這領域的決心。
第二篇生物醫學資訊科技帶領醫療數位轉型,是由張明台所撰寫,其為亞大基因科技創辦人,此篇撰寫就可以看出偏重資訊架構面在建置基因定序服務於實驗室會需要考慮和面對的狀況。
這篇文章

- 資訊科技應用在生物資料上有很重要的角色,如何選擇演算法工具、統計方法,資料儲存和管理的方式,是否建置資料湖泊(data lake),怎麼處理排成、運算資源最佳化、數據安全性、流程是否符合法規。
- 建置臨床基因檢測實驗室包含了生物資訊分析設計、IT軟硬體系統建置,以及維運的中央實驗室,本質上技術含量極高,且跟傳統的醫療專業相當不同
- 全球基因體學和健康聯盟(Global Alliance for Genomics and Health, GA4GH)的研究,在2025年,在臨床醫療場域將會有超過4750萬罕見疾病基因體,以及8300萬癌症基因體被定序,到2027年將有70%的癌症診斷檢測,使用基因定序分析。
- 如何將半導體產業的自動化電子設計(Electronic design automation)觀念,導入臨床生物資訊的流程設計,且能有功能驗證與確校,如何做好自動化流程設計。
- 使用基因定序資料來計算同源重組修復缺失(Homologous recombination deficiency, HRD),包含使用單核甘酸變異(Singel nucleotide variants)、小片段插入缺失變異(Short insertion and deletion)、複製數變異(Copy number variation)、大片段基因重組(Large genomic rearrangement)
- 分享美國國家衛生研究院柯林斯2021年在Cell雜誌分享對於2030年精準醫療的看法(Precision medicine in 2030 – seven ways to transform healthcare)
- 巨量的縱貫長期的世代研究資料
- 群體的生物多樣性
- 大數據與人工智慧
- 例行性臨床基因定序檢測
- 電子健康紀錄
- 表現型體學與環境因子
- 隱私、信任與價值回顧
第三篇 以『次世代定序』完成精準醫療,更能協助生命科學領域的探索 由中央大學生醫科學與工程學系系統生物與生物資訊博士候選人 趙盈婷和中央大學生醫科學與工程學系副教授 許藝瓊撰寫,此篇就聚焦在次世代定序的介紹和與過去定序技術的比較和微生物箘群
- 基本上,要先有資料,才有辦法有所謂的“資訊”,所以生物進入大數據時代,高通量定序技術絕對扮演重要角色,從第一代的定序技術桑格定序於1977年發行,到約2005-2007年開始有次世代定序技術,整個領域進步飛快
- 次世代定序中,illumiina公司的技術算是主流,其只要是使用所謂的sequeing by synthesis的概念來打大規模定序。
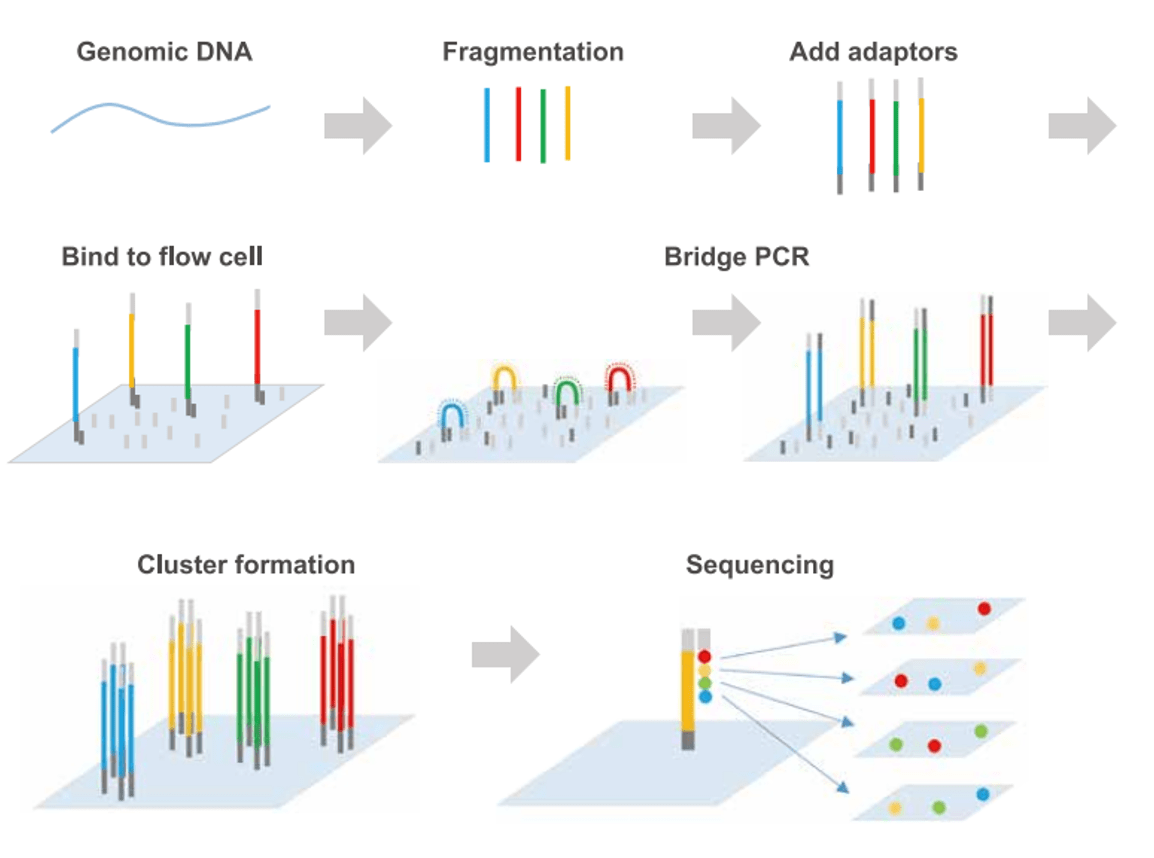
- 次世代定序也開始被應用在不只人類疾病研究上,傳統微生物學研究,必須仰賴培養和後續的生化分類,或是簡單使用16s定序,如今使用次世代定序則依次可以探索檢體內所有的微生物核酸序列,美國腸道協會(American Gut Consortium)在2012年推出美國人腸道計畫(American Gut Project),其在2018年發表了第一個全面性的人類微生物體學資料庫,影響大眾開始對人體微生物群的興趣。
- 同時,也可以利用此技術來研究環境中的微生物群體,免去培養等培養難題
第四篇學習生物資訊學要具備哪些能力,是李御賢教授的專訪,由科學月刊總編輯林翰佐採訪撰稿
- 李御賢老師是國內很早期開始做生物資訊方向研究的學者從基因維陣列到後面的次世代定序資料,參與過SARS-COV病毒序列研究、史帝文森症候群的印務基因體學研究等等
- 現在的生物資訊學家需要具備建立程式管鍊(pipeline)的能力,串連很多程式進行分析,且具備撰寫批次檔案的技能。
- 建議對於生物資訊學有興趣的人可以從三項能力來培養
- 基本建立分析管線能力Pipeline
- 資料視覺化之技能
- 基本生物學的基本素養
- 生物資訊領域進步迅速,需要不段的累積新的知識和能力